고정 헤더 영역
상세 컨텐츠
본문
728x90
머신러닝에 필요한 라이브러리 설치
$ pip install -c conda-forge scikit-learn
$ pip install pandas
$ pip install numpy라이브러리 Import
import pandas as pd
import numpy as np학습 목표와 데이터 살펴보기

학습 목표 : 연봉예상
데이터 : YearsExperienceSalary, Salary
1. 데이터 확인

데이터는 얼마나 있을까?

2. 데이터 가공
학습을 시키기 위해 주어질 데이터 X와 예측할 데이터 y로 나눠주어야 한다.

3. 데이터 분리
X,y의 데이터를 이제 train(학습용),test(확인용)로 나눠주어야 한다.
하지만 여기서 주의해야 하는 것은 데이터를 잘 섞어주어야 학습이 잘 될 수 있다.
예를 들어 3+2와 같은 일의 자리로 덧셈을 가르친 학생은 백의 자리의 문제 풀 기 어렵다는 것
sklearn의 라이브러리를 이용하여 섞어주면 일일히 내가 문제를 섞지 않아도 랜덤하게 섞일 수 있다.
from sklearn.model_selection import train_test_split
# test_size -> 테스트셋을 몇의 비율로 나눠줄지
# random_state -> 어떻게 랜덤하게 나눠줄지
X_train, X_test, y_train, y_test=train_test_split(X,y, test_size=0.2, random_state = 5)각각의 데이터를 확인해 본다.
train셋

test 셋

잘 섞였다. 의심스러워서 처음에는 위의 데이터와 비교해봤다
역시 컴퓨터를 의심하지는 말자 개고생이다.

X 데이터 즉 모델에 주어질 데이터들이 현재 1차원인데, 데이터들을 2차원을 바꿔주어야 한다.
인공지능에 필요한 데이터는 2차원이기 때문이다.
X_train = X_train.values.reshape(-1,1)
X_test = X_test.values.reshape(-1,1)
더보기
1차원 데이터를 넣으면 이러한 오류가 난다
Expected 2D array, got 1D array instead: array=[ 1.5 4.1 9.5 7.1 10.3 1.1 5.3 2.9 1.3 9.6 4. 6.8 6. 8.7 3.2 2.2 3.2 3.7 5.1 7.9 3. 4.9 4.5 2. ]. Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
4. 피쳐스케일링
필요한 작업이나 linearlinear안에는 피쳐스케일링이 되어 들어간다.
굳이 내가 고생할 필요가 없다!
2021.05.06 - [coding/머신러닝] - [머신러닝] sklearn으로 쉬운 Feature scaling 피처 스케일링
[머신러닝] sklearn으로 쉬운 Feature scaling 피처 스케일링
컴퓨터는 생각보다 정교한 것 같다. 간단하게 학습 데이터에 두개이상의 데이터가 들어간다고 가정했을 때 하나의 데이터가 10000의 단위가 다른 데이터가 1의 단위라면 정답이 더 큰 단위의 데
golduny.tistory.com
5. 모델 학습
이제 linearRegression을 불러와 train데이터로 학습을 시킨다.
# 모델 불러오기
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
# 학습
regressor.fit(X_train, y_train) # regressor.fit(문제지, 답)6. 예측하기
test데이터는 학습시 들어가지 않은 데이터이므로 모델에 넣어 학습률이 얼만큼 되는지 확인할 수 있다.

답안지를 가지고 있으므로 채점을 해본다.
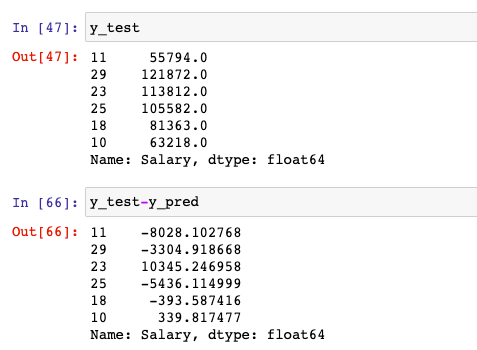
그래프로 오차율이 얼마나 되는지 확인해 보았다.

'coding > 머신러닝' 카테고리의 다른 글
| [머신러닝] Label Encoding / One-Hot Encoding (0) | 2021.05.17 |
|---|---|
| [머신러닝]Multiple Linear Regression (0) | 2021.05.17 |
| [머신러닝] sklearn으로 쉬운 Feature scaling 피처 스케일링 (0) | 2021.05.06 |
| [머신러닝]Linear Regression (0) | 2021.05.04 |
| 머신러닝 supervised/unsupervised (0) | 2021.05.03 |




